Earth Engine + Cloud Run + Redis
A few months back I posted my experiments deploying serverless Earth Engine functions using infrastructure-as-code with Pulumi. Here, I’m building on that code to add a Redis instance that will allow us to cache server-side computations, reducing the number of EE calls and speeding up responses.
The Goal
I’m going to build on the original demo function, which computed the cloud cover of the most recent Landsat 9 image (you can still run it here).
If you run it a few times, you’ll notice the result doesn’t change much. That’s because Landsat is ingested into Earth Engine in daily batches. As a result, we’re wasting CPU time on our serverless function and on Earth Engine by recomputing it every time that it’s invoked, when the result isn’t likely to change.
To solve that, we can introduce a caching layer1. The first time the function is called, it will compute the result and store it in the cache. Subsequent invocations can check the cache and either 1) return the previous result without ever touching Earth Engine servers, or 2) replace it with a new computed value once it becomes stale.
Our stack will look something like this, using Memorystore for Redis to handle caching while staying in the Google Cloud ecosystem, which will simplify communication between components:
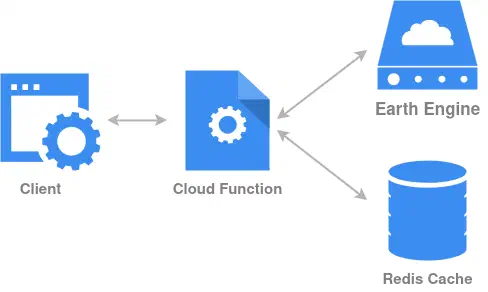
With the infrastructure planned, we can start writing the Pulumi code to deploy it.
Infrastructure as Code
Some of this is going to look familiar if you read the previous blog post, so I’ll just briefly go over each component here, which are all contained in a __main__.py file at the project root.
Enable APIs
For security, a default Google Cloud project can’t do much. We’ll need to enable each of the required API services first.
import pulumi
import pulumi_gcp as gcp
def enable_apis() -> list[gcp.projects.Service]:
"""Enable all APIs required for the stack."""
return [
gcp.projects.Service(f"{api}-api", service=f"{api}.googleapis.com")
for api in [
"vpcaccess",
"cloudbuild",
"cloudfunctions",
"earthengine",
"run",
"redis",
]
]
Create Credentials
Our cloud function will need be authenticated to run Earth Engine, which we’ll do with a service account and corresponding key.
def build_service_key() -> gcp.serviceaccount.Key:
"""Create a service account and key for the function."""
account = gcp.serviceaccount.Account(
"service-account",
account_id="demo-service-account",
display_name="Demo Service Account"
)
return gcp.serviceaccount.Key(
"service-key",
service_account_id=account.name,
)
Construct a VPC
A virtual private network (VPC) will allow our function to communicate with our Redis cache without any need for additional authentication.
def build_vpc(
apis: list[gcp.projects.Service],
) -> tuple[gcp.compute.Network, gcp.vpcaccess.Connector]:
"""Build a VPC and connector to allow communication between function and cache."""
vpc = gcp.compute.Network(
"vpc",
auto_create_subnetworks=True,
opts=pulumi.ResourceOptions(depends_on=apis),
)
vpc_connector = gcp.vpcaccess.Connector(
"vpc-connector",
ip_cidr_range="10.8.0.0/28",
machine_type="f1-micro",
min_instances=2,
max_instances=3,
network=vpc.self_link,
region="us-central1",
)
return vpc, vpc_connector
Note that we’re passing in apis and making our Network depend on them. Pulumi builds infrastructure in parallel, so this dependency ensures that the network isn’t built before the required vpcaccess service is enabled. Otherwise, you’d get a build error the first run.
Set Up a Cache
Now we can build the Redis cache, which itself depends on the VPC to allow communication with other components.
def build_cache(vpc: gcp.compute.Network) -> gcp.redis.Instance:
"""Build a Redis cache instance."""
return gcp.redis.Instance(
"redis-cache",
memory_size_gb=1,
region="us-central1",
replica_count=0,
tier="BASIC",
authorized_network=vpc.self_link,
)
Build the Cloud Function
The last piece of our architecture is the cloud function itself. This will turn local source code (which we still need to write) into a serverless function. This component will need access to:
- The VPC for communication with the cache.
- The cache’s host and port address.
- The service key credentials.
The last two we’ll set as environment variables in the function runtime.
def build_cloud_function(
*,
path: str,
vpc_connector: gcp.vpcaccess.Connector,
cache: gcp.redis.Instance,
key: gcp.serviceaccount.Key,
) -> gcp.cloudfunctionsv2.Function:
"""Build a Cloud Run function that talks to the cache via the VPC."""
src_bucket = gcp.storage.Bucket(
"src-bucket",
location="US",
)
src_archive = gcp.storage.BucketObject(
"src-archive",
bucket=src_bucket.name,
source=pulumi.asset.FileArchive(path),
)
cloud_function = gcp.cloudfunctionsv2.Function(
"cloud-function",
location="us-central1",
build_config={
"runtime": "python311",
"entry_point": "main",
"source": {
"storage_source": {
"bucket": src_archive.bucket,
"object": src_archive.name,
},
},
},
service_config={
"max_instance_count": 1,
"available_memory": "128Mi",
"timeout_seconds": 5,
"environment_variables": {
"REDIS_HOST": cache.host,
"REDIS_PORT": cache.port,
"SERVICE_ACCOUNT_KEY": key.private_key.apply(lambda k: base64.b64decode(k).decode()),
},
"vpc_connector": vpc_connector.name,
"vpc_connector_egress_settings": "PRIVATE_RANGES_ONLY",
},
opts=pulumi.ResourceOptions(depends_on=[cache]),
)
gcp.cloudrun.IamBinding(
"cloud-function-invoker",
location=cloud_function.location,
service=cloud_function.name,
role="roles/run.invoker",
members=["allUsers"],
)
return cloud_function
We’ve defined how the function will be built, but not the function itself. That’s up next.
Write The Cloud Function
What do we actually want to run in cloud? First, we need a way to compute cloud cover in Earth Engine, after initializing with the service account from our exported environment variable. Here’s that function, in a new Python script.
import datetime
import os
import ee
def calculate_last_cloud_cover() -> float:
"""Calculate the cloud cover of the last Landsat 9 image."""
key_data = os.environ["SERVICE_ACCOUNT_KEY"]
credentials = ee.ServiceAccountCredentials(None, key_data=key_data)
ee.Initialize(credentials)
now = datetime.datetime.now(datetime.timezone.utc).timestamp() * 1000
last_cloud_cover = (
ee.ImageCollection("LANDSAT/LC09/C02/T1")
.filterDate(now - 172_800_000, now)
.sort("system:time_start", False)
.first()
.get("CLOUD_COVER")
)
return last_cloud_cover.getInfo()
Next, we’ll need to connect to the Redis cache to store and retrieve computed values, which we’ll accomplish with the redis-py and our host/port environment variables:
import redis
try:
redis_host = os.environ["REDIS_HOST"]
redis_port = int(os.environ["REDIS_PORT"])
redis_client = redis.Redis(
host=redis_host,
port=redis_port,
socket_connect_timeout=5,
)
# Confirm that the client is connected
redis_client.ping()
except Exception as e:
logging.error(e, exc_info=True)
redis_client = None
Now we can write the entry point function that orchestrates between Redis and Earth Engine:
import logging
from flask import jsonify
import functions_framework
@functions_framework.http
def main(_):
if redis_client is None:
return jsonify({"error": "Internal error"}), 500
last_cloud_cover = redis_client.get("last_cloud_cover")
if last_cloud_cover is None:
from_cache = False
try:
last_cloud_cover = calculate_last_cloud_cover()
redis_client.set("last_cloud_cover", last_cloud_cover, ex=3600)
except Exception as e:
logging.error(e, exc_info=True)
last_cloud_cover = -1.0
else:
from_cache = True
last_cloud_cover = float(last_cloud_cover)
return jsonify(
{
"last_cloud_cover": last_cloud_cover,
"from_cache": from_cache,
}
)
After checking for a valid Redis connection, we try to pull a value from the cache by the last_cloud_cover key. If that doesn’t exist (either because this is our first run or the previous value expired) we compute a new value and write it to the cache. Using ex=3600 tells Redis that the new value is only valid for one hour – after that, Redis will return None, triggering a new computation.
Finally, we return a JSON response with the cloud cover value and whether or not it came from the cache, to help with debugging.
Deploy!
Back in __main__.py, the final step is to put together all the infrastructure components and point our function to the source code we just wrote:
apis = enable_apis()
vpc, vpc_connector = build_vpc(apis)
cloudrun = build_cloud_function(
path="./src",
vpc_connector=vpc_connector,
cache=build_cache(vpc),
key=build_service_key(),
)
pulumi.export("function-url", cloudrun.url)
Running pulumi up will build each of the infrastructure components in the required order, and several minutes later we have a URL to the newly deployed cloud function.
Invoking the function once returns a fresh, uncached value. Subsequent calls run much quicker, returning the cached cloud cover:
{
"from_cache": true,
"last_cloud_cover": 34.59
}
When you’re done, you can run pulumi destroy to remove the infrastructure2.
It’s worth pointing out that Earth Engine does its own share of server-side caching, but implementing our own will be more configurable and much faster, since we won’t need to authenticate and wait for their servers. ↩︎
Unlike Cloud Run functions which scale to zero, Memorystore is always running and has no free usage tier. The bare-minimum configuration above cost about $1 USD per day when deployed. ↩︎